Apache Kafka's Cloud-Native Future
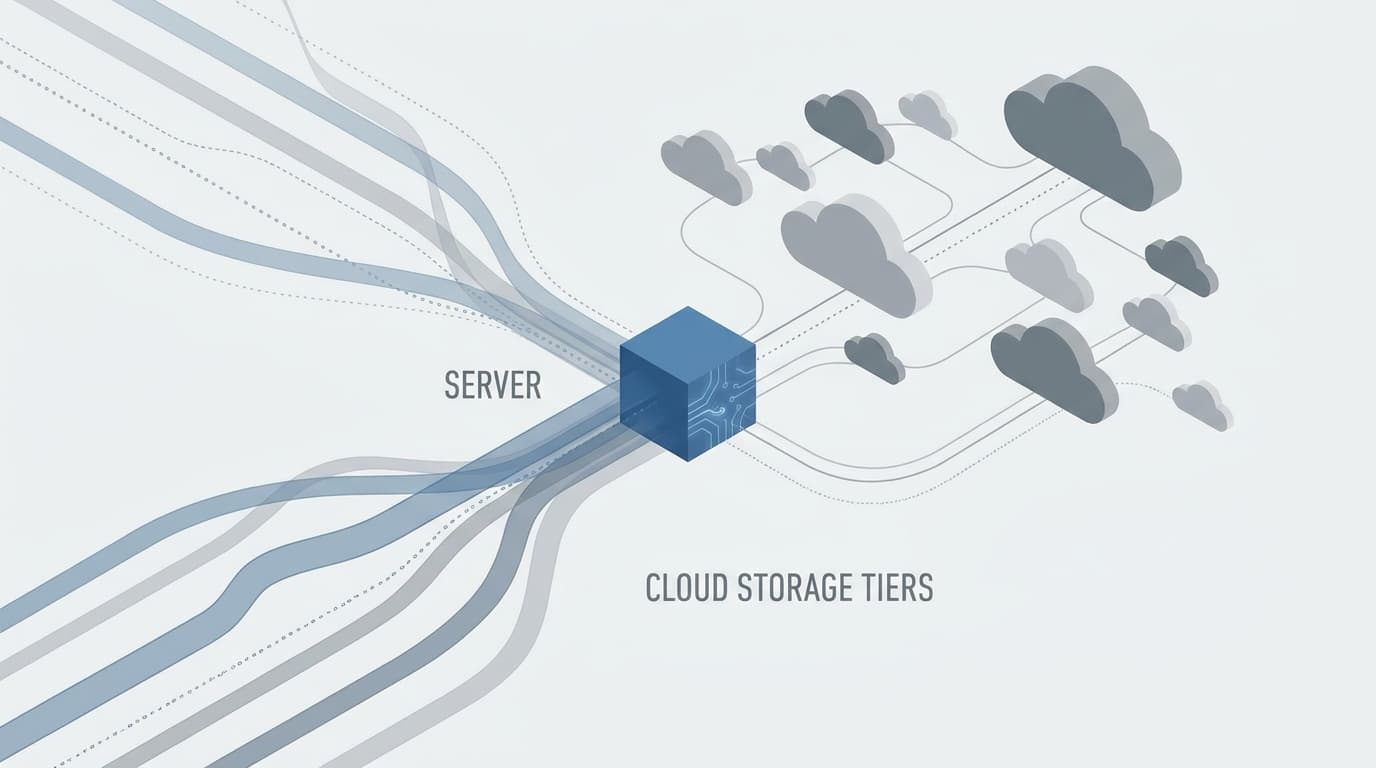
TL;DR: Apache Kafka is evolving into a cloud-native platform. This shift involves tiered storage for cost efficiency, better financial operations (FinOps) telemetry, and elastic scaling. Architects are also exploring a future where Kafka could operate without local disks, changing its core operational model.
Key facts
- Category
- Infrastructure
- Impact
- High
- Published
- Source
- InfoQ
Full summary
Apache Kafka is shifting to a cloud-native architecture, using tiered storage and exploring a diskless future to improve cost and operational efficiency.
Apache Kafka is undergoing a significant architectural transformation to better align with cloud-native principles. This evolution introduces key features like tiered storage, which allows Kafka to offload older data to cheaper object storage, reducing local disk requirements and costs. Other important developments include enhanced FinOps telemetry for better cost visibility, elastic consumer scaling to handle variable workloads, and the introduction of virtual clusters and Share Groups. These features collectively aim to make Kafka more flexible, scalable, and economically viable in modern cloud environments where resources are managed dynamically.
These changes are crucial for developers and operations teams managing large-scale event streaming platforms. By decoupling compute and storage, the new architecture simplifies operations and improves cost-efficiency. This shift fundamentally alters the economic model of running Kafka, making it more sustainable for a wider range of use cases. Looking ahead, the community is also exploring a potential "diskless" future where brokers would rely entirely on remote storage. While this could maximize elasticity, it introduces new trade-offs in latency and performance that architects must consider for the long-term trajectory of event streaming platforms.
Tags
Related on Notifire
Related stories
Primary source: InfoQ